

Table of contents
I know, I know building ML Applications is fun yes, but have you ever tried training a model with limited data? huhhh?
Web Crawler:

Being able to get data however and whenever you want is 🔥.
Today, we’ll be looking into how I reverse engineered stockx’s web and mobile api, to get more historical data on items.
WHY?
It’s common knowledge that stockx is the fountain of data when it comes to sneakers sale’s history. You can get whatever you want, right on there!
Super Amazing right?
Case Study
Let’s take a look one of my favourite kicks of all time, drum rolls…
The Jordan 1 Retro High OG
Overview
As with every webpage you want to crawl, we need to get an overview of what this page looks like, know what data we’d want to extract.
I can’t speak for you, but I definitely dont want to store every single thing on that page 😆.

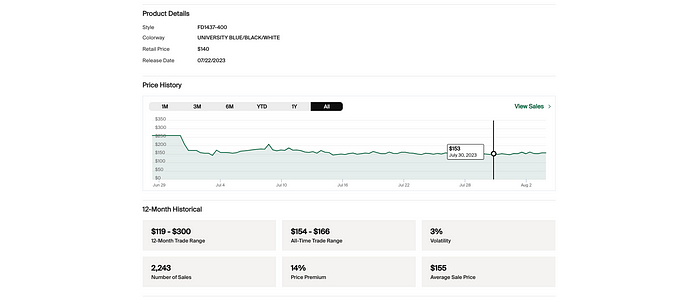

You see it already right? So much meaningful data 💃 💃 💃
What Do We Want To Scrape
As you might’ve guessed already, we want store:
Title of this sneaker
Breadcrumb of this page, just so we know all the tiny little categories 😅
Style
Retail Price
Release Date,
Colorway
Sales History
- date
- time
- size
- price
And of course, you can add more fields, whatever you want!